

Can a Single Neuron do MNIST?
perhaps someday soon

Recently, a group of neuroscientists (Beniaguev, Segev, & London) showed that it takes a seven layered neural network (128 channels per layer) to accurately predict the spike train of a single, layer 5 pyramidal neuron.
This is somewhat surprising: most people (including neuroscientists) believe neurons to be far less computationally complex than this. In fact, when estimating comparisons between artificial neural networks and human brains, most people assume something like a one to one mapping between nodes in a network and neurons in a brain, with neurons contributing as little as 1 FLOP per second.
If this paper is right, that in fact a single neuron is as complex as a seven layered network, this would significantly extend timelines that are anchored in biology. For instance, Carlsmith’s report on the computational power of the human brain estimates that it uses around 1e15 FlOPs, but that treating the results of the above paper as true would push it to 1e21 FLOPs (6 orders of magnitude more!)
Carlsmith doesn’t feel that confident about these results: they’re the only one of their kind, and he isn’t sure how relevant extra complexities like dendritic computation are to the overall computational task the brain is doing. Still, he thinks it’s one of the largest uncertainties in his model, and would plausibly update a lot if he became more confident about it.
One drawback of the initial paper is that they can’t be sure that they found the smallest network. They tried a bunch of them, but of course any search over network architectures (nodes per layer, number of layers, hyperparameters, etc.) isn’t exhaustive. Perhaps it truly does take a seven layered network, but perhaps not. Still, it’s suggestive.
A better test of the computational capacity of a single neuron would be to try to get it to do something that a seven layered network can do, e.g., classifying digits. If it’s capable of that, then this is stronger evidence of the claim “one neuron is as computationally complex as a small neural network.”
The same group (Beniaguev, Shapira, Segev, and London) tried this a few months ago. The rest of this post reviews this paper.
First of all, I think the idea of training a single neuron to do a task is new to this paper. It’s not, as far as I know, commonplace to think something like this is even possible. This is why, I think, they choose to simulate a neuron that’s less computationally complex (and less realistic) than the one used in the previous paper (the layer 5 pyramidal cell).
The neuron they do model in this paper is called a Filter and Fire (F&F) neuron, which is a Leaky Integrate and Fire (I&F) neuron with a few more bells and whistles. I don’t know exactly what an I&F neuron is, but I don’t think it’s that relevant for this analysis.
Interestingly, neurons usually synapse onto their postsynaptic neuron multiple times! I didn’t know this. Many neuroscientists have concluded that this is just a redundancy thing: it helps to have multiple points of contact in case one fails. But, for reasons I won’t get into, the authors think there’s a strong case for these being computationally relevant aside from redundancy. So, they model their neuron with this in mind.
The F&F neuron is thus an I&F neuron except that it allows multiple dendritic connections from a single neuron and it has different filters at each synapse according to location. This is a schematic of what it looks like:
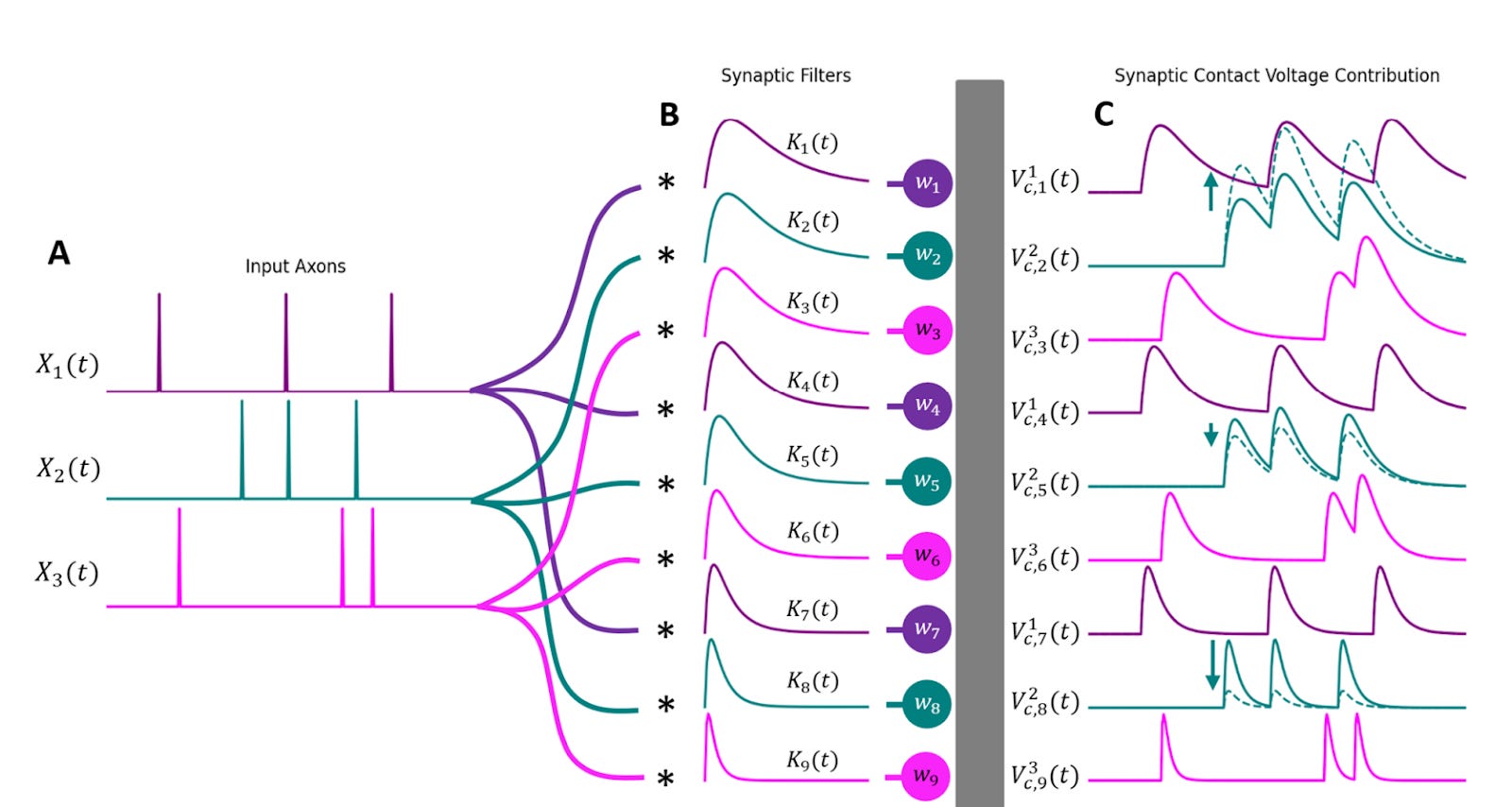
Essentially, spike trains will come in from the neurons synapsing onto the neuron in question (on the left). These will connect at multiple points along the axon. At each point, the spike train will pass through a filter (the K functions), which are broader the further away they are from the cell soma (not pictured), and tighter the closer they are. These convolutions applied to the incoming spike trains create what you see on the right (the V functions). Finally, all of these are multiplied by a weight which determines how much influence they have on the firing decision.
So, at the end of the day, you can think of the function of inputs (multiple spike trains) to decision to fire as a number : V(t)*W. Taking a bunch of these outputs in succession creates a spike train.
How the hell does this thing learn MNIST? Well, first things first, they turn the MNIST dataset into a temporal dataset, where the width of each image is converted into 2 ms time bins, like so:

The height of each image is the input, so for instance, any dense vertical line, like on the 4, represents each pre-synaptic neuron firing at the same time.
Once they have this setup, where a particular set of spike trains corresponds to, e.g., the number 3, they “train” the neuron to take up weights which give the right output (a spike train which only fires an action potential within 10 ms of seeing the correct number), as seen below:

Training isn’t really training. They just set up a logistic regression to find the best weights. I don’t think this matters too much—I’m mostly interested in whether or not a structure computationally ~equivalent to a neuron can do the task at all, not whether the training process is biologically feasible.
How well does this set up do? Well, the F&F fares much better than the I&F model, and is comparable to the performance of a non-biological model (spatiotemporal logistic regression). In the figure below, M represents the number of connections each axon makes to the cell, T is the time presentation of each stimulus (digit).

At first glance, this seems pretty impressive: F&F is doing well above 90% accuracy for each digit! Then, you might notice that the baseline is set to 90% for most digits, so is it really that good after all?
First of all, I’m pretty unclear on why the baseline is at 90%. As far as I can tell from snooping around their code, the baseline is calculated by taking the percentage of how many non-correct answers there are relative to correct ones, so, e.g., if you’re trying to randomly guess and there are 10 total numbers, you’ll have a ~90% chance of getting it wrong (which seems sensical). But this would suggest that the baseline of guessing correctly is ~10%? I’m surely missing something here. Regardless, an accuracy of over 90% seems impressive to me.
Secondly, I’m pretty sure (although it would take me on the order of an hour to figure it out) that they “train” each digit classifier separately—so, e.g., the weights for predicting the spike train for the number 3 will be different from those of predicting the number 8.
This seems much less impressive to me—it doesn’t even really seem like you’re classifying digits at that point, just predicting some arbitrary binary vector. It seems very likely, for instance, that the neuron doesn’t really “understand” anything about the digits and that it doesn’t do anything interesting with them in the way that a neural network would (e.g., edge detection). So, even if it can classify them correctly, is it really as “computationally complex”?
My guess is that, no, it’s certainly not. But I still think this paper is an update for me. This neuron model is essentially a point neuron model with some extra complexities (convolutions, multiple connections) which all neural networks use. It’s surprising to me that you can get it to do digit classification at all. Would you have guessed that a single perceptron could classify digits? Or rather, classify a single digit? This model is more biologically plausible than the point neuron, but still, it’s suggestive.
I would not conclude, from this alone, that neurons can “do MNIST,” I think there’s still a lot of work to be done. But my guess is that, with a more biologically plausible neuron (e.g., the layer 5 cells they used in the previous paper), this might be accomplished—and in a way that’s more general and computationally interesting than the model in this paper. I believe this group is working on that now, so stay tuned!
It would also be really interesting to see whether or not a real neuron could do MNIST. I’m not sure how one would do this, or if it’s even possible. Perhaps you could find the weights by doing this logistic regression “training” and then map those onto a neuron in a petri dish? Like I said earlier, I don’t think anyone has really thought about how to train a single neuron—it’s just not an idea that’s crossed anyone’s mind. So, I think it’s really cool that these scientists are looking into it. It’s an interesting hypothesis and one that could considerably affect AI timelines. We’ll see!